2023. 2. 24. 12:42ㆍ디지털장사
연관키워드를 불러오기 위해서는 일단 ajax 라는 것을 사용해야 한다고 함,
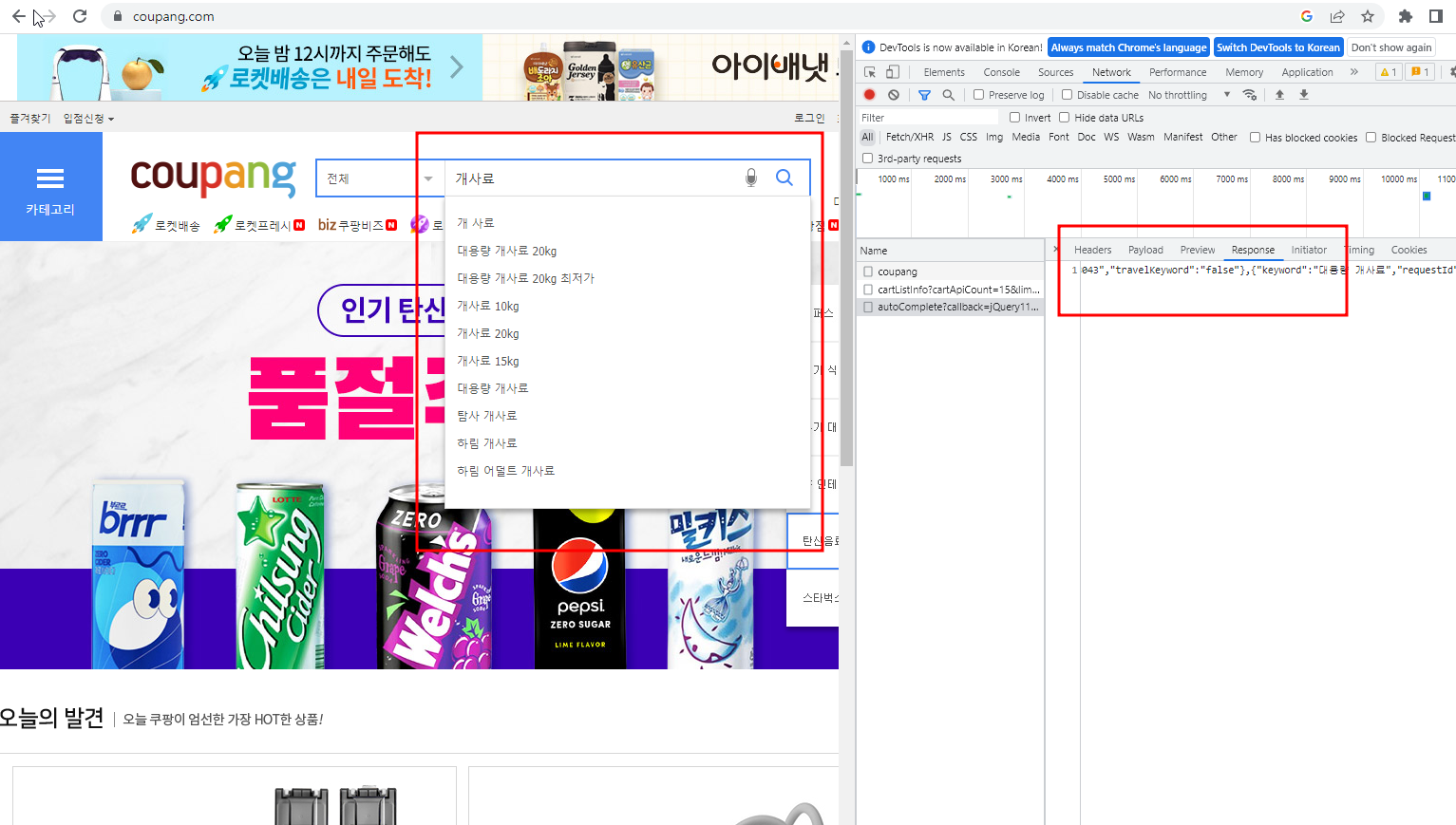
홈페이지 접속후 원래라면 새로고침을 하여야 나타나는데 실시간으로 반영하는 것이 ajax 라고 이해하였다.

잘 설명이 되어있다.
이런 프로그램을 만들려고 하는 이유는 너무 불편해서, 너무 오래걸려서, 가공하기 편하려고 하는 여러 이유가 있다.
일단 시도할것은 쿠팡을기준으로 하려고 함.
준비물 = (파이썬 깔기, 파이참 설치)

일단 요렇게 세게를 임포트
만약에 이게 없으면 설치를 해야 한다

터미널에서
pip install 내가쓰려고하는 도구
이게 기본명령어 인데 이렇게 하면 설치 가 안되는 경우도 있다.
그럴땐 인터넷 검색을 하면된다.
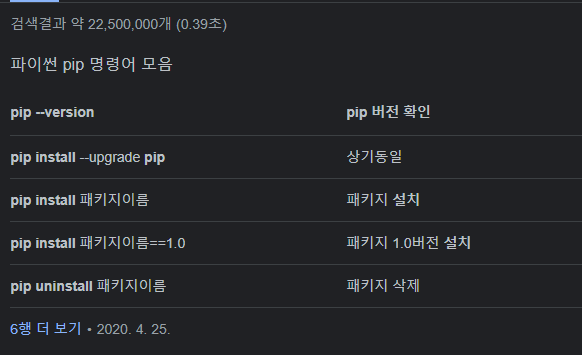
| pip --version | pip 버전 확인 |
| pip list | 설치된 패키지 목록 확인 |
| python -m pip install --upgrade pip | pip 업그레이드 |
| pip install --upgrade pip | 상기동일 |
| pip install 패키지이름 | 패키지 설치 |
| pip install 패키지이름==1.0 | 패키지 1.0버전 설치 |
| pip uninstall 패키지이름 | 패키지 삭제 |
| pip search 패키지이름 | 패키지 검색 |
| pip install --upgrade 패키지이름 | 패키지 업그레드 |
| python --version | 파이썬 version 확인 |
| python 실행 후 exit() | 파이썬 version 확인, 32/64비트 확인 |
이제 시작

쿠팡으로가 사진과 같이 내가 가져올 키워드 주소를 찾아야 한다.
변수 = 키워드
request.get(f"사이트-----{변수 }-----") -이런식의 형식이다.

크게 보면 헤더에 있는 URL 주소를 복사한다.
keyword = pyautogui.prompt("키워드 입력")이건 주소에 넣을 키워드 변수
그리고 아래와 같이 f스트링을 사용하여 주소에다가 적당히 넣어줌
아까 복사한 주소는 requests.get 괄요 안에다가 넣어준다.
r_coupang = requests.get(f"https://www.coupang.com/np/search/autoComplete?callback=jQuery111105082177076737822_1677140976179&keyword={keyword}&_=1677140976186")
coupang_data = r_coupang.text그리고 쿠팡에서 추출한 값중 텍스트값만(string) 추출한후 다시 변수에 저장한다.
이것을 print(coupan_data) 로 출력하면
jQuery111105082177076737822_1677140976179([{"keyword":"개 사료","requestId":"8a93ec8970f4445f93e2dfeb2d58e967","travelKeyword":"false"},{"keyword":"대용량 개사료 20kg","requestId":"8a93ec8970f4445f93e2dfeb2d58e967","travelKeyword":"false"},{"keyword":"대용량 개사료 20kg 최저가","requestId":"8a93ec8970f4445f93e2dfeb2d58e967","travelKeyword":"false"},{"keyword":"개사료 10kg","requestId":"8a93ec8970f4445f93e2dfeb2d58e967","travelKeyword":"false"},{"keyword":"개사료 20kg","requestId":"8a93ec8970f4445f93e2dfeb2d58e967","travelKeyword":"false"},{"keyword":"개사료 15kg","requestId":"8a93ec8970f4445f93e2dfeb2d58e967","travelKeyword":"false"},{"keyword":"대용량 개사료","requestId":"8a93ec8970f4445f93e2dfeb2d58e967","travelKeyword":"false"},{"keyword":"탐사 개사료","requestId":"8a93ec8970f4445f93e2dfeb2d58e967","travelKeyword":"false"},{"keyword":"로얄캐닌 개사료","requestId":"8a93ec8970f4445f93e2dfeb2d58e967","travelKeyword":"false"},{"keyword":"대형견 대용량 개사료 20kg 최저가","requestId":"8a93ec8970f4445f93e2dfeb2d58e967","travelKeyword":"false"}])
위와 같이 출력이 된다.
다시 여기서 리스트 형태로 가공하는 과정이 필요하다 .
dic_coupang = json.loads(str_coupang)
요 함수를 이용해서 간단하게 바뀌었다.
바꾸는 이유는 앞에있는
coupang_data이 변수는 스트링 값이고
변형된 값
dic_coupang 이 변수는 리스트 형이기 때문에 포문에서 하나씩 꺼내주면 가공이 된다
정리하면 스트링값은 모두 출력되기 때문에 어짜피 엑셀해서 정리해 주어야 하는데 너무 힘들더라
그래서 계속 간단한 방법이 없을까 하다 이방법을 발견했다.
이제 포문으로 추출만 해주면 된다.
try:
for i in dic_coupang:
print(i['keyword'],end =",")
y = y + 1
print(y)
except:
print("쿠팡은 정말 없는것 같애요")아까 가공한 쿠팡 상품 리스트에서 "," 을 이용하여 분리해 주었다. end = " "는 print 함수를 출력하면 끝에 기본적으로 엔터가 들어가는데 그거 넣지말고 ","요거로 대체해 주세요 라고 부탁하는 명령어?(부탁어?) 라고 한다
예외처리 문구를 넣은것은 값이 없으면 애러가 나더라
전체코드 정리:
import requests
import json
import pyautoguikeyword = pyautogui.prompt("키워드 입력")r_coupang = requests.get(f"https://www.coupang.com/np/search/autoComplete?callback=jQuery111105082177076737822_1677140976179&keyword={keyword}&_=1677140976186")coupang_data = r_coupang.texttry:
str_coupang = coupang_data.split("jQuery111105082177076737822_1677140976179(")[1][:-1]
except:
print("쿠팡은 없는것 같애요")try:
dic_coupang = json.loads(str_coupang)
except:
print("쿠팡은 정말 없어요")print("쿠팡 ",end = ":")
try:
for i in dic_coupang:
print(i['keyword'],end =",")
y = y + 1
print(y)
except:
print("쿠팡은 정말 없는것 같애요")전체 함수 인데 여기서 y 변수는 밖에 넣어주었다.
이유는 카운터 때문이다.
네이버 키워드 기준으로 총 10개가 들어갈수 있는데 10개가 넘어가면 하나씩 세어야 하기 때문에 귀찮아서 카운터를 넣어주었다.
실행 키워드 :개사료

쿠팡 :개 사료,대용량 개사료 20kg,대용량 개사료 20kg 최저가,개사료 10kg,개사료 20kg,개사료 15kg,대용량 개사료,하림 개사료,탐사 개사료,개사료 5kg,10
방금 말한것 처럼 맨뒤에 10개가 카운터 되는 모습이다.
끝
'디지털장사' 카테고리의 다른 글
| 바나나b2b 엑셀 크로울링 (이셀러스활용2) (0) | 2022.11.15 |
|---|---|
| 바나나 도매사이트 크로울링 해보기 (이셀러스 활용계획) (0) | 2022.11.14 |
| python으로 엑셀 EMS2.0 카테고리 넣기 메모 이셀러스 형식 도매창고에서 받아 수정 (0) | 2022.11.08 |
| 이셀러스 상품등록 오류 메모(스마트스토어) (0) | 2022.08.09 |